Youngjoon Jang
M.S. Student at NLP&AI Lab, Korea University

yjoonjang34@gmail.com
Hi, I’m Youngjoon. I’m a Master’s student in NLP&AI Lab at Korea University, advised by Prof. Heuiseok Lim. Before this, I studied Mechanical Engineering & Computer Science at Hongik University.
I’m drawn to a deceptively simple question: how can I help people find the right information? That curiosity drives my work in Information Retrieval (dense, sparse, and late-interaction retrieval), Multilingual Information Retrieval, and Retrieval-Augmented Generation (RAG). My research has been published at SIGIR, ICLR, ACL, and EMNLP, while the Korean retrieval models and benchmarks I led have grown to 200+ GitHub stars and 1.3M+ downloads on Hugging Face.
I love building in the open, and I actively contribute to projects including Sentence-Transformers, MTEB, and InstructKR.
News
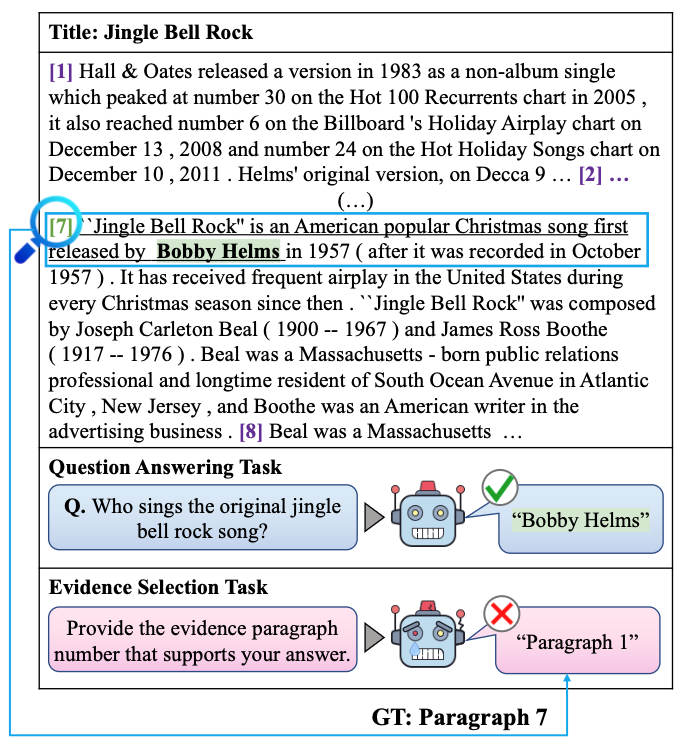
| Apr 02, 2026 | Our paper “Beyond Hard Negatives: The Importance of Score Distribution in Knowledge Distillation for Dense Retrieval” has been accepted to SIGIR 2026 🇦🇺 |
|---|---|
| Mar 02, 2026 | Our paper “Improving Semantic Proximity in Information Retrieval through Cross-Lingual Alignment” has been accepted to ICLR 2026 🇧🇷 |
Education
Projects
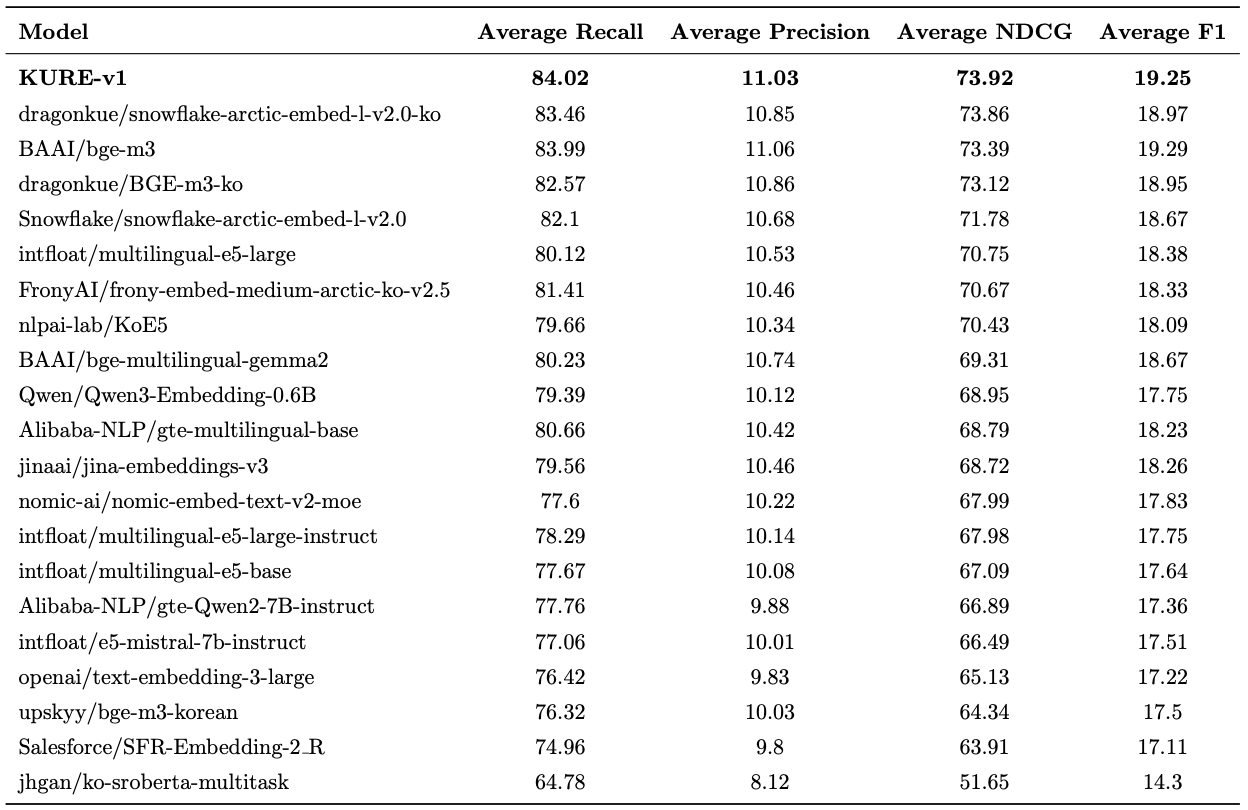
KURE: Korea University Retrieval Embedding Model (GitHub · HF)
Led the flagship Korean retrieval project — trained SOTA dense retriever (1st on MTEB-ko-retrieval), 200+ GitHub stars and 1.3M+ cumulative Hugging Face downloads. Awarded Best Oral Presentation at HCLT 2025.
Korean ColBERT & Sparse Retrievers (colbert-ko-v1 · splade-ko-v1 · inference-free-splade-ko-v1)
Trained and open-sourced Korean ColBERT and SPLADE variants achieving SOTA among corresponding architectures on the Korean Retrieval Benchmark.
PreRanker (GitHub · HF)
Trained a lightweight reranker for tool retrieval in LLM agents, narrowing candidate tools before downstream execution. Achieved a 3.1% relative improvement in tool-retrieval Recall@10, enabling accurate candidate filtering for agent tool selection.
URACLE–Korea University Collaborative Research
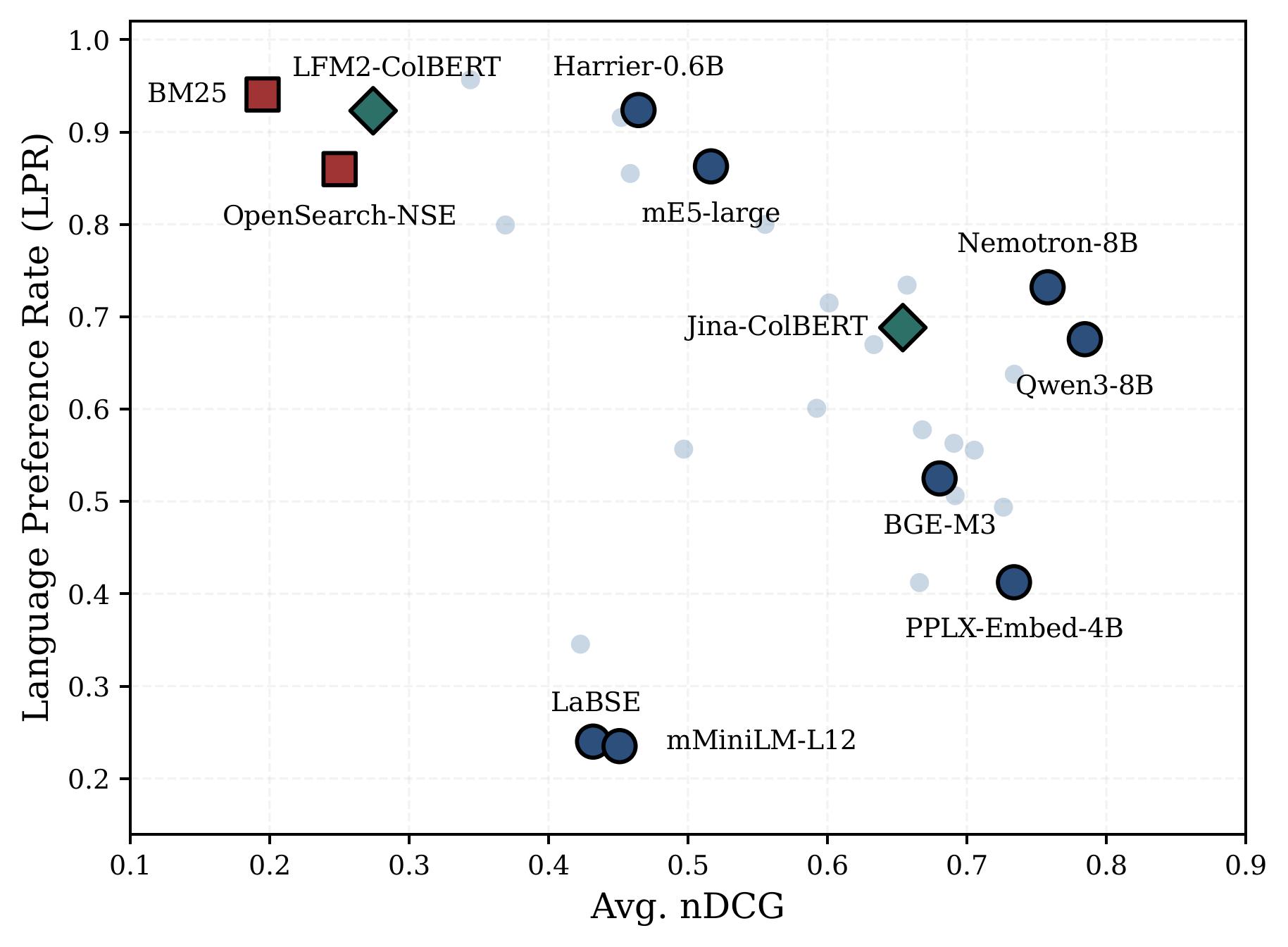
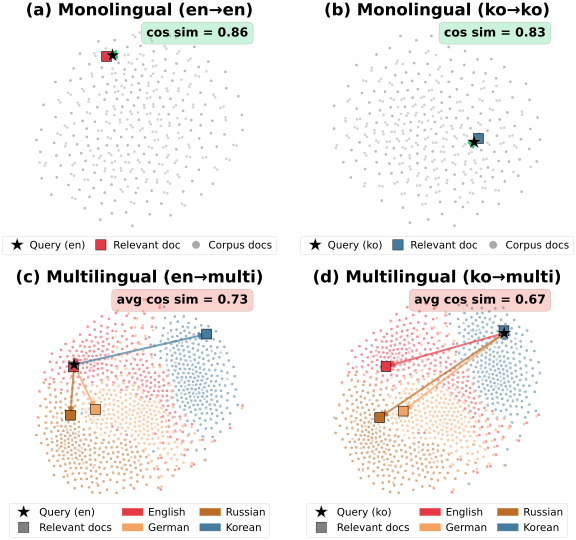
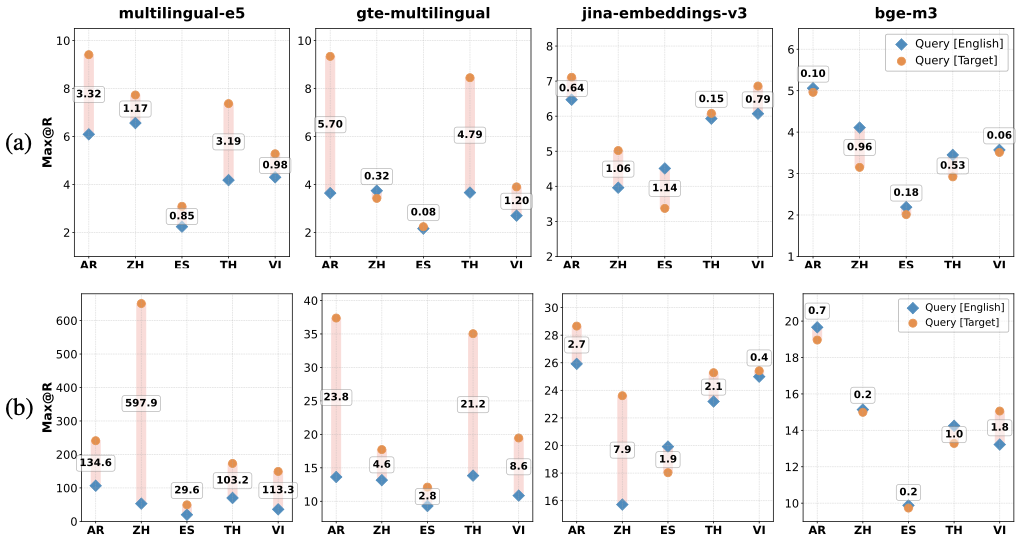
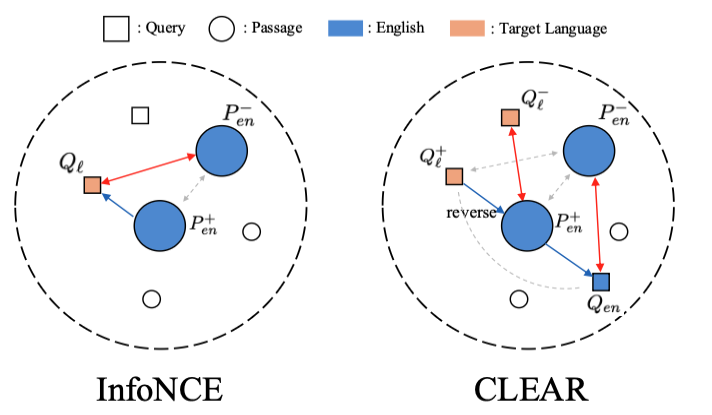
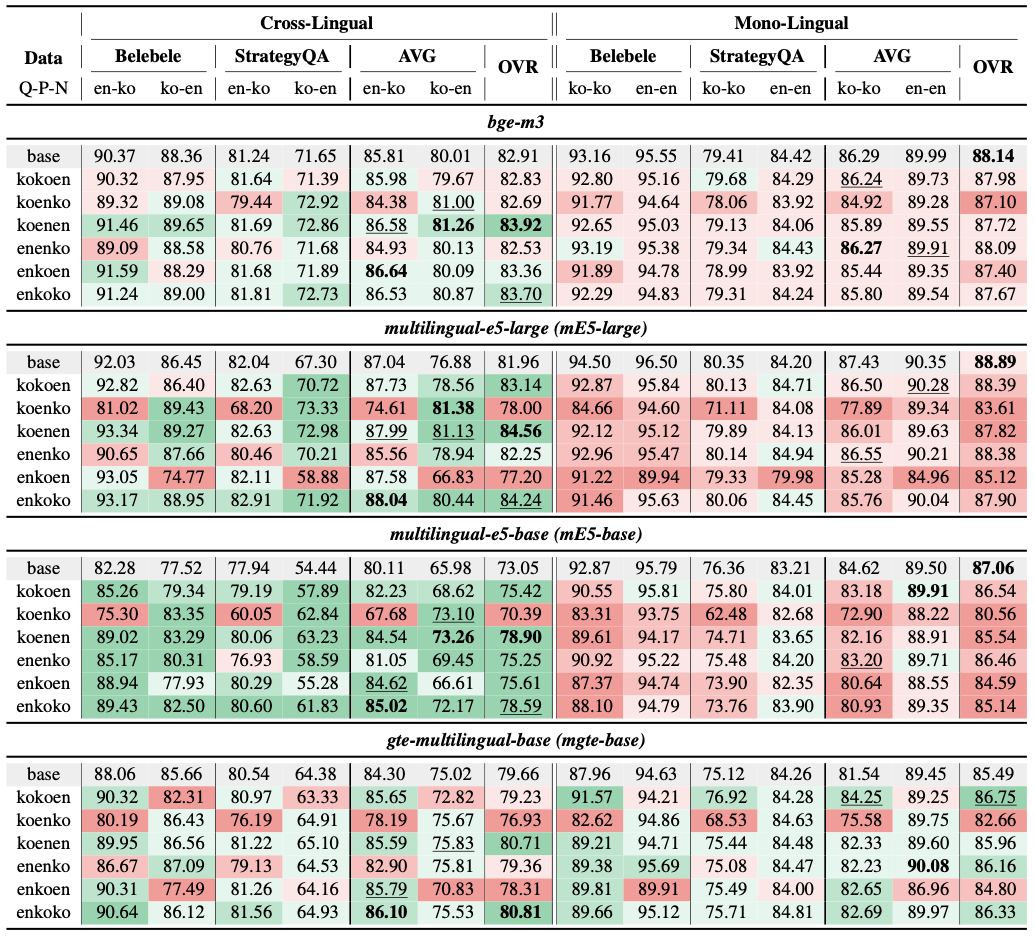
Trained a Korean–English cross-lingual retrieval embedding model and analyzed language-pair trade-offs; used model merging to recover monolingual retrieval while retaining cross-lingual retrieval gains. Published in the ACL 2026 MeLLM Workshop.
WBL: World Best LLM Project (HF)
Led the data team: built a query-clarity tagging & evaluation framework, and a reward-model-ensemble response-filtering pipeline for large-scale training data.
KT–Korea University Collaborative Research (Korean Legal LLM) (News)
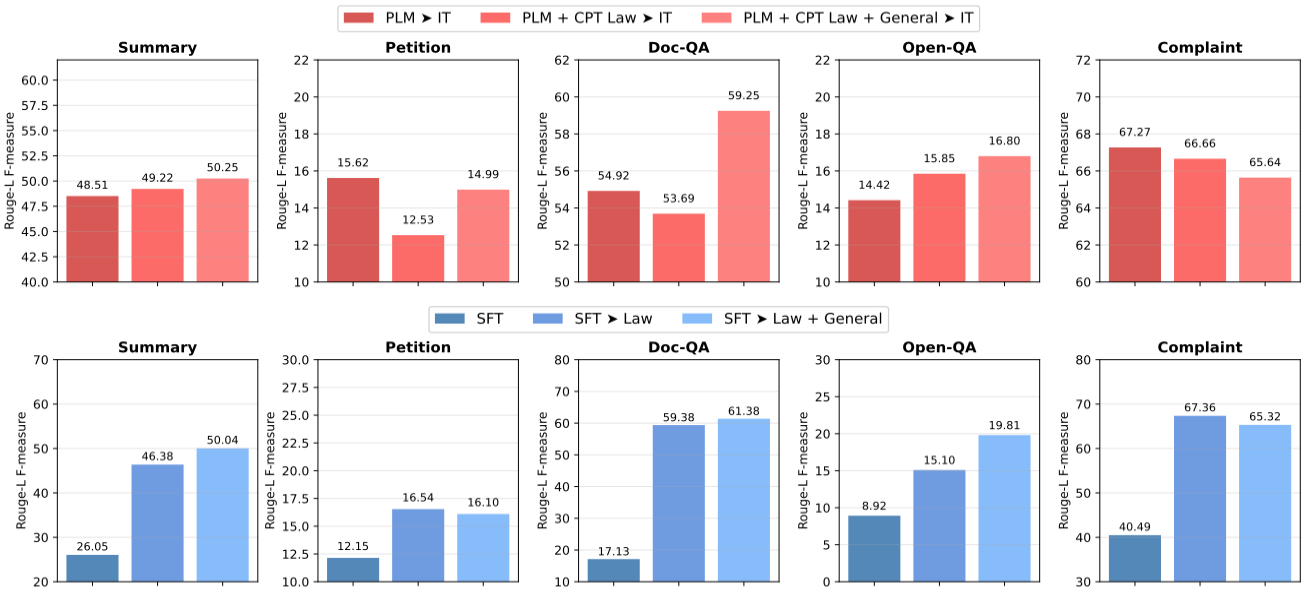
Developed an end-to-end training recipe for a Korean legal-domain LLM, published as LEGALMIDM (ICLR 2026 Data-FM Workshop); contributed to KT's $10.42M contract for the South Korean Supreme Court AI platform.
Open Source Contributions
- Extended the cross-encoder training stack with classic learning-to-rank losses (RankNetLoss, ListMLELoss, Position-Aware ListMLELoss).
- Implemented EmbedDistillLoss for direct embedding-level knowledge distillation.
- Introduced hardness-weighted contrastive learning for hard negatives.
- Implemented CachedSpladeLoss for memory-efficient SPLADE training.
MTEB (Massive Text Embedding Benchmark)
- Added a Korean retrieval benchmark task (AutoRAGRetrieval).
- Improved OpenAI embedding wrapper stability.
- Fixed NaN embeddings for Jasper models.
- Led the Korean Reranker evaluation and leaderboard project.
Publications [Conference]
- In Proceedings of the 49th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2026
- In Proceedings of the 14th International Conference on Learning Representations (ICLR), 2026
- In International Conference on Learning Representations Addressing Data Problems for Foundation Models Workshop (ICLR Data-FM Workshop), 2026
- In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL), 2026
- In Annual Meeting of the Association for Computational Linguistics Workshop on Multilinguality in the Era of Large Language Models (ACL MeLLM Workshop), 2026
- In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics: Student Research Workshop (ACL SRW), 2025
- In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024


Publications [Domestic Conference]
- In The 37th Annual Conference on Human & Cognitive Language Technology (HCLT), 2025
- In The 36th Annual Conference on Human & Cognitive Language Technology (HCLT), 2024